
TL; DR:
- AI needs ontologies, not raw data models, to decide well
- Platform ontologies govern how the system reasons and operates
- Domain ontologies map enterprise concepts to systems of record
- An ontology’s authority comes from validation and deterministic verification, not from formality alone
- Scope Questions, the specific questions a decision-maker needs answered, reduce 100,000 tables to a limited set of concepts that matter and a two-proof coverage gate makes that reduction verifiable, not asserted
- Ontologies are living configuration: generated in hours, validated by experts, extended continuously, and governed by verification gates
2. The Ontological Infrastructure
Part 1 of this series described what Decision Narratives require: formal representations of intent, assumptions, Roles, process, and domain knowledge, organized around a structured hierarchy and sustained over time. This section describes the ontological infrastructure that makes those requirements concrete.
2.1 Why Ontologies Matter
Enterprise decisions rarely depend on a single system. A sales forecast may require CRM data, ERP data, support metrics, documents, emails, and institutional knowledge distributed across multiple systems of record.
The challenge is not a lack of information. The challenge is that the information required to decide is fragmented across these systems. Before analysis can begin, information must be located, reconciled, and connected across multiple sources. This cross-system labor has become one of the largest sources of inefficiency in modern enterprises.
Large language models appear well-suited to this challenge because they can consume information from many sources and generate coherent answers. However, enterprise decision-making requires more than plausible responses. It requires consistency, completeness, provenance, explainability, and reliable reasoning across disparate systems.
Every LLM already contains a latent ontology: an internal representation of concepts such as revenue, customer, pipeline, churn, and risk learned from vast amounts of public data.
Consider a simple question:
“What was our Q1 revenue?”
Salesforce may contain $120M in closed-won opportunities. NetSuite may report $95M in recognized revenue. A finance spreadsheet may exclude professional services revenue. A board reporting package may normalize foreign exchange fluctuations.
All these values could reasonably be described as revenue, yet they produce different answers to the same question. Without an explicit ontology, the model has no authoritative basis for determining which definition should be used. The result may be inconsistent across users, incomplete because relevant adjustments were omitted, or incorrect because data from different systems was combined using incompatible definitions.
An ontology is a formal representation of concepts, relationships, constraints, and business meaning. It gives the system an authoritative basis for dramatically reducing exactly the kind of ambiguity the revenue example illustrates.
But ontologies alone are not sufficient. They must operate within a broader semantic layer that transforms business meaning from unstructured artifacts into explicit, machine-understandable structures
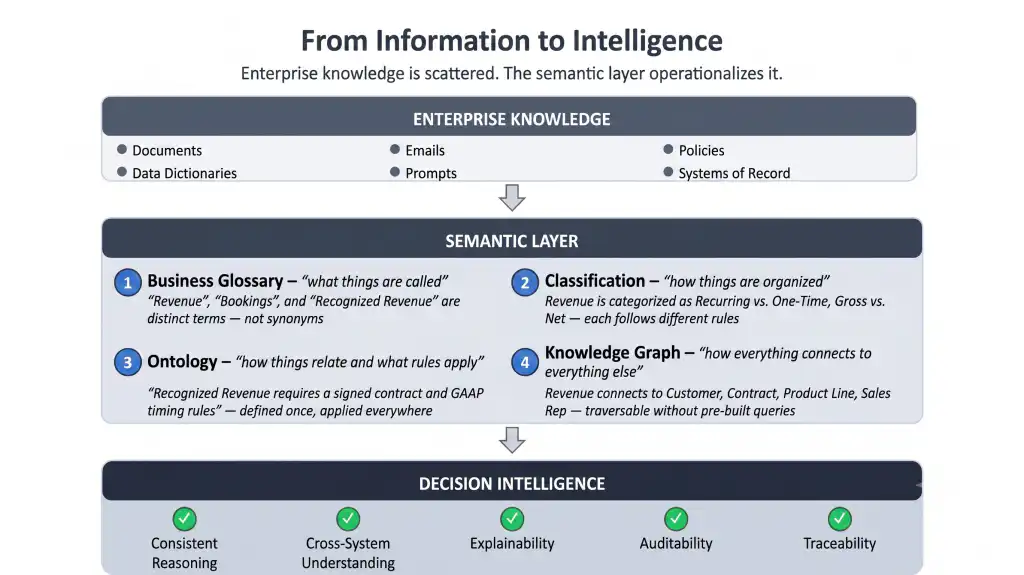
Most enterprises already have business knowledge scattered across documents, spreadsheets, policies, prompts, and systems of record. These artifacts contain meaning, but they do not operationalize it. Every user, application, and AI agent must interpret that meaning for itself, every time.
The semantic layer makes meaning explicit, shared, and machine-understandable — so that humans and AI systems reason consistently across domains and systems. That is what makes Decision Intelligence auditable and trustworthy at enterprise scale.
We envision the architecture that organizes this infrastructure into two tiers: platform ontologies, which are domain-agnostic and govern how the system itself operates, and domain ontologies, which capture the concepts that matter within a specific Sphere (a bounded decision domain such as sales, finance, or portfolio management).
2.2 Platform Ontologies: The Machinery of Decision-Making
Platform ontologies define the semantic infrastructure of the Decision Intelligence system itself. Without them, the system cannot distinguish an assumption from a constraint, a Scope Question from a follow-on question, or a monitoring trigger from an approval gate. Four platform ontologies are essential:
Process Ontology: Formalizes workflow stages, agent tasks, decision points, orchestration patterns, execution traces, and quality gates. When a workflow advances from evidence-gathering to evaluation, that transition is a typed event in the process ontology, not an implicit state change hidden in application code.
Intent Ontology: Formalizes user query types, task classifications, information needs, and analytical goals. This ontology enables agents to classify and interpret user intent formally, routing queries to the correct processing pipelines. It is the foundation for scope-question matching.
Profile and Narrative Ontology: Formalizes user profiles, organizational structures, Role definitions, and the Decision Narrative hierarchy described in Section 1.3 of Part 1. It defines how Roles relate to spheres, how assumptions attach to narrative levels, and how beliefs propagate through the hierarchy.
Provenance Ontology: Formalizes where every piece of information came from and how it was derived. Every claim in a decision output links back, step by step, to the specific records in the source systems that produced it. This is what makes explainability a structural property rather than an after-the-fact narrative: when a decision-maker asks “where did this number come from?”, the answer is retrieved, not reconstructed. The same structures underpin governance and audit — compliance reviews and lineage requirements query the provenance record directly, so what the system asserted, what it consulted, and who approved what remain inspectable at any point after the fact.
Upper-Level Alignment (gist): All three platform ontologies are anchored to gist, the open upper-level business ontology developed by Semantic Arts, which provides foundational categories including Event, organization, Agreement, Category, and Magnitude. We deliberately build on gist rather than inventing our own upper layer: it is mature, minimal, and business-oriented. To be precise about what this anchoring delivers: a shared upper ontology ensures structural coherence — every class traces to a common superclass path, properties are type-consistent, and alignment can be audited automatically. It does not, by itself, guarantee full semantic interoperability between independently built domain ontologies; that is what the explicit alignment audits, overlap detection (which identifies at least 90% of semantic overlaps when integrating standards such as FIBO), and human review in our lifecycle exist to deliver.
Platform ontologies are not optional infrastructure. Without the process ontology, agent behavior cannot be formally verified. Without the intent ontology, Scope Questions cannot be classified or matched. Without the profile and narrative ontology, the Decision Narrative hierarchy has no formal representation, and the Role-based tailoring described in Section 1.6 of Part 1 reduces to ad hoc prompt engineering.
2.3 Domain Ontologies: The Language of the Sphere
Where platform ontologies describe how the system works, domain ontologies describe what it works with. A domain ontology captures the concepts, relationships, and constraints that matter within a specific sphere. Domain ontologies serve two essential functions.
Grounding reasoning in domain terms: When an agent reasons about a portfolio’s risk exposure, it needs formal entities like Asset Class, Sector, Duration, Credit Rating, and Correlation. These are not generic data labels. They are domain entities with defined relationships, constraints, and assumptions. The domain ontology makes these explicit and machine-processable, enabling agents to reason about domain entities rather than raw data values.
Mapping disparate data schemas to common meaning: Enterprise data is distributed across multiple systems, each with its own schema and naming conventions. A company’s revenue might be stored as Total_Revenue in one database, REV_AMT in another, and Amount (filtered by transaction type) in a third. The domain ontology translates between these schemas, ensuring the system retrieves the same concept regardless of source.
Rather than inventing domain vocabularies from scratch, the generator can take established standards — FIBO for finance, SNOMED CT for healthcare — as inputs, extending and specializing existing concepts instead of duplicating them. Together with the gist upper ontology, this grounds the generated ontology in vocabularies that domain experts already recognize and trust.
2.4 Automated Ontology Generation: The Key to Scalability
If the system is to scale across multiple spheres, domain ontology development cannot be a purely manual, expert-driven process. Hand-crafting ontologies is expensive and time-consuming and would make multi-domain scalability impractical.
The infrastructure includes an ontology generator that produces an initial domain ontology largely automatically, with human-in-the-loop validation and refinement rather than human-driven construction. The generator takes a domain name, a domain description, and a set of Scope Questions as inputs, and produces a working initial ontology. Optional inputs include an existing upper ontology, prior domain ontologies, and data model schemas, all of which improve output quality and accelerate system-of-record mapping.
The human-in-the-loop pattern is deliberate. The generator handles the labor-intensive structural work of identifying entities, inferring relationships, and aligning to data schemas. Domain experts focus on the judgment-intensive work of verifying semantic accuracy and adding institutional nuance that no generator can infer from descriptions alone.
The core differentiator: This approach transforms domain onboarding from a months-long manual ontology engineering project into a process that produces a working initial ontology in hours, with progressive refinement over the following weeks as the system is used and as continuation questions extend coverage into areas the initial generation did not anticipate.
2.5 How the Two Tiers Interact
Platform and domain ontologies interlock through well-defined extension points. The process ontology defines what a decision checkpoint is in abstract terms; the domain ontology defines what passing the risk assessment checkpoint means in the context of investment due diligence. The intent ontology classifies a user question as a valuation inquiry; the domain ontology defines which entities, such as Valuation Multiple, Discounted Cash Flow, and Enterprise Value, are relevant to that classification.
This design allows the platform to be domain-agnostic at its core while deriving domain-specific capability from externally provided knowledge structures. Adding a new domain requires developing a domain ontology for that sphere and connecting it to the existing platform ontologies through the upper-level alignment. With the ontology generator, this process can be bootstrapped in hours.
3. The Ontological Scale Problem
3.1 Why Data Models Are the Wrong Starting Point
The conventional approach to connecting AI to enterprise data begins with the data model: expose the schema, allow the model to understand the tables and columns, and let it generate queries against the underlying systems of record. While this appears intuitive, at enterprise scale, it fails in three predictable ways.
First, AI systems become overwhelmed by schema complexity.
Salesforce, including Sales Cloud, Service Cloud, and Data Cloud, spans hundreds of interconnected objects and thousands of attributes. A typical SAP ERP installation contains over 100,000 database tables spanning finance, materials management, sales, and HR. Asking an AI to answer a question about vendor payment terms by reasoning over the full SAP schema is comparable to finding a specific passage in a library by handing someone the complete card index. These are not edge cases. They are the standard data environments of mid-to-large enterprises.

Faced with this scale, the model must determine which systems are relevant, which tables should be queried, which joins should be performed, and which fields matter for the question being asked. The combinatorial search space becomes enormous. As complexity grows, errors become increasingly common and increasingly difficult to detect. The DELEGATE-52 finding that distractor context is one of the largest contributors to model degradation is the empirical face of this problem: handing a model 98% irrelevant schema is handing it distractors at massive scale.
Second, signal is diluted by irrelevance.
Most enterprise questions require only a tiny fraction of the available data model. A question about revenue concentration risk may require access to less than two percent of the underlying schema. Yet without an explicit mechanism for determining relevance, the AI must reason across a much larger universe of possible tables, fields, and relationships.
The challenge compounds rapidly at enterprise scale. The larger the schema, the more difficult it becomes to identify the small fraction of data relevant to a particular decision. As the search space expands, cross-system labor increases and the probability of error rises. AI is more likely to select incorrect tables, construct invalid joins, misinterpret relationships, or overlook critical evidence hidden within the surrounding noise
Third, data models describe storage structures, not business meaning.
Even when the correct data is located, enterprise systems rarely encode the semantic relationships required for decision-making. A customer may appear as an Account in Salesforce, a Customer in NetSuite, a Business Partner in SAP, and a named entity in contracts or emails. Humans understand that these representations often refer to the same underlying concept. The data models do not.
As a result, exposing larger portions of enterprise schemas to an LLM does not fundamentally solve the problem. It simply gives the model more structures to navigate without providing a principled understanding of what those structures mean.
The challenge is therefore not merely one of data access. It is a problem of scale, relevance, and semantics. Solving it requires an intermediary layer that can identify what matters, map concepts across systems, and provide a shared understanding of business meaning before AI reasoning begins.
3.2 Context Windows and Practical Constraints
Modern large language models operate within finite context windows. Even the largest cannot accommodate the full schema of a system like SAP alongside the user’s question and reasoning chain. Techniques like schema summarization and retrieval-augmented generation help but do not resolve the fundamental issue: without knowing what is relevant before querying, the system must either include too much and dilute the signal or include too little and risk missing what matters. This is the ontological scale problem, and closing it requires a different starting point entirely.
4. Scope-Question-Driven Ontology
4.1 Starting from Questions, Not Data
The answer to the scale problem begins not with data, but with the Scope Question: the specific question a decision-maker needs answered within a given Sphere and Role.
For example: What is the revenue concentration risk in our top ten accounts? Or how has gross margin trended quarter-over-quarter, and what are the primary drivers of change?
Each Scope Question implies a narrow ontological footprint: a small set of entities, relationships, and data sources necessary and sufficient to answer it. A question about revenue concentration requires entities like Account, Revenue, Time Period, and Concentration Metric, mapped to specific tables in the CRM and ERP. It does not require the hundreds of other objects in those systems that deal with marketing campaigns, service tickets, or warehouse logistics.
By beginning with Scope Questions rather than data models, the approach inverts the conventional method. Instead of starting with everything and trying to filter down, it starts with what matters and maps outward only as far as needed.
4.2 Building Scope-Question Ontologies
A scope-question based ontology is a lightweight, purpose-built domain ontology that captures exactly the entities, relationships, and system-of-record mappings needed to answer a defined set of questions within a sphere. Building such an ontology involves three steps:
Scope Question elicitation: Scope Questions are initially seeded by domain experts during onboarding. A portfolio analyst might define questions like: What is the current P/E ratio relative to sector median? Or: What are the key risk factors flagged in the most recent 10-K filing? These expert-seeded questions are then refined by usage patterns as the system observes which questions are actually asked, which follow-ons are common, and where gaps emerge.
Ontological modelling: For each cluster of Scope Questions, the relevant entities, relationships, and constraints are modelled as a lightweight ontology anchored to gist to ensure structural coherence. The modelling captures not just what entities exist but how they relate, what constraints govern them, and what assumptions underlie their use. The entity Revenue in a SaaS context, for instance, carries assumptions about recognition timing, recurring versus one-time classification, and currency normalization that must be explicit in the ontology. These assumptions connect directly to the Decision Narrative framework, as they are the domain-level assumptions that propagate through the hierarchy described in Part 1.
System-of-record mapping: Each entity in the scope-question ontology is mapped to specific tables, fields, and access patterns in relevant systems of record. Account Revenue might map to the Opportunity object in Salesforce (filtered by closed-won stage and close date) and to specific line items in the SAP FI module. These mappings are bidirectional: given an entity, the system knows where to find the data; given a data source, the system knows what entities it can serve.
4.3 System-of-Record Mapping Is Engineered, Not Assumed
We want to be clear about this step, because it is the graveyard of most enterprise data-integration efforts: custom fields, schema drift, revenue-recognition edge cases, and per-tenant deviations are exactly where months disappear. Our architecture treats mappings as a first-class, governed engineering artifact, factored into two layers:
Generic SoR libraries. For each supported system of record and version (e.g., NetSuite 2024.1, Salesforce Sales Cloud, Anaplan), we maintain a standard mapping set — expressed in W3C R2RML — that binds the role ontology to the standard objects and fields of that SoR. These libraries are built once, versioned alongside the ontology, and reused across every customer running that system. They are the high-leverage asset that lets a new customer onboard in days rather than months: the heavy lifting is done before the customer arrives.
A thin customer-specific overlay. Per-customer deviations — custom fields like Revenue_Adjusted__c, custom objects, tenant-specific conventions — are handled by a thin overlay generated through automated schema diff against the canonical SoR model, LLM-assisted and human-confirmed. The overlay lives in the customer’s namespace and never modifies the canonical ontology, so one customer can run on version 1.4.0 of a role ontology while another runs 1.5.0.
At query time, a virtualization engine loads the generic mappings plus the customer overlay and translates ontology-level SPARQL into SQL pushed down to the actual systems — which means the LLM never sees table names at all. It expresses intent in business vocabulary; the pre-validated mapping, not the model’s guess, produces the SQL. Schema drift is an explicit, monitored update trigger (a new SoR version, a new column in a customer table) that flows through the same verification gates as any other ontology change, rather than a silent breakage discovered in production.
4.4 How This Diminishes the Scale Problem
The scope-question ontology acts as a relevance filter between the AI system and the enterprise data model. When a question is asked, the system does not reason about the full schema. Instead, it matches the question against known Scope Questions or their intent maps, identifies the relevant ontological entities, and follows the system-of-record mappings to retrieve exactly the data needed.
Consider the question: What drove the margin decline in Q3? In a data-model-first approach, the AI must reason about which of possibly hundreds of tables contain margin-relevant data, construct queries, and hope it selected the right joins. In the scope-question based approach, the system recognizes this as a margin analysis Scope Question, activates the relevant entities (Gross Margin, Cost of Goods Sold, Revenue by Product Line, Operating Expenses by Category), and follows pre-defined mappings to the specific tables in the ERP and financial reporting systems. The AI focuses on interpreting the data, not navigating the schema.
Return to the revenue question from Section 2.1. In the scope-question approach, the system recognizes the intent behind “What was our Q1 revenue?”, activates the appropriate entity and follows appropriate mappings in NetSuite — not the closed-won pipeline in Salesforce. The four conflicting numbers collapse to one, because the ontology has already resolved which definition applies.
4.5 The Incompleteness Reality
No initial ontology will be complete. Domain experts cannot anticipate every question that will arise, and the business environment evolves. A scope-question ontology built for standard investment due diligence will not initially cover questions about the implications of a newly announced regulatory framework or the competitive dynamics of an emerging technology sector. This incompleteness is a design parameter that must be handled gracefully.
The critical architectural decision is how the system behaves when a question exceeds the current ontology’s coverage. These are continuation questions: questions that arise naturally during a decision process but extend beyond the entities and mappings the ontology currently supports.
4.5.1 Continuation Questions and Hybrid Inference
Continuation questions can be handled through a three-stage escalation:
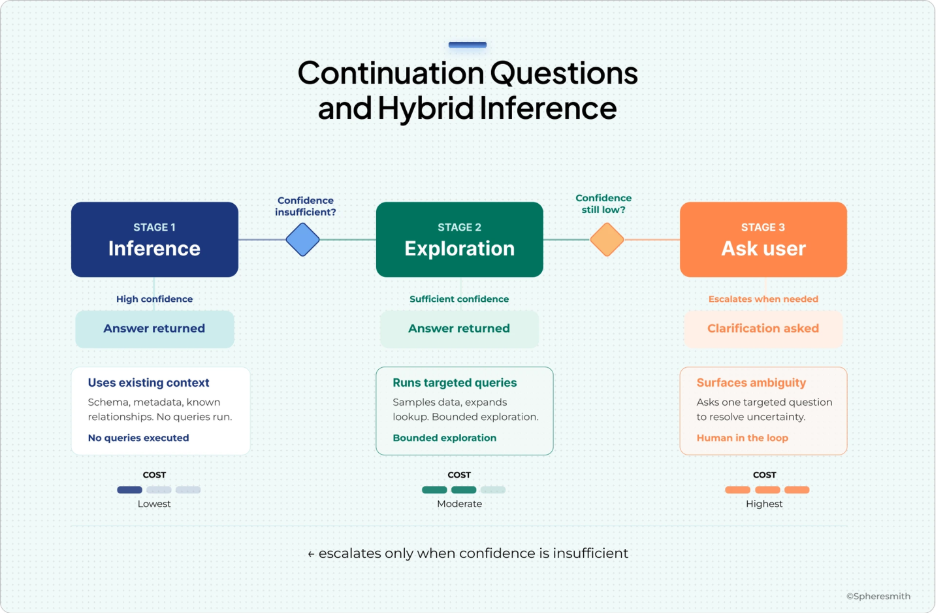
Stage 1: Ontological inference
The system first attempts to answer the continuation question using inference over the existing ontology. If the question asks about an entity closely related to existing entities, such as free cash flow yield when the ontology already contains free cash flow and market capitalization, the system can often infer the necessary derivation without extending the ontology.
This covers a significant proportion of continuation questions, particularly those that involve derived metrics or alternative views of existing data.
Stage 2: Autonomous data-model exploration
When inference over the existing ontology is insufficient, the system explores the underlying data models, guided by the existing ontology as an anchor. The data model has been pre-processed and indexed with table and field descriptions, usage patterns, and relationship metadata to support targeted exploration.
Stage 3: User interaction
If confidence remains below a defined threshold after Stage 2, the system surfaces the question to the user with a structured explanation of what it found, why it is uncertain, and what specific clarification would resolve the ambiguity. The user’s response is incorporated directly into the ontology, promoting the new entity through the standard validation path.
This three-stage approach preserves the efficiency of the ontology-first method for known questions while providing a principled degradation path for novel ones. Over time, resolutions from Stages 2 and 3 feed back into the ontology, extending coverage and reducing the frequency of costly data-model exploration.
5. Architectural Implications
5.1 The Semantic Intermediary Layer
The framework described in this blog implies a distinct architectural layer between the AI reasoning system and the enterprise data infrastructure. This semantic intermediary layer maintains the platform and domain ontologies, hosts the ontology generator for domain bootstrapping and extension, manages system-of-record mappings, executes the three-stage continuation protocol, and evolves ontological coverage over time.
This layer carries a semantic state: it knows what entities exist in each sphere, how they relate, what assumptions govern them, and where the data lives. The ontology generator is a core capability of this layer, invoked during initial domain onboarding and during ongoing operation when the continuation protocol identifies gaps that warrant targeted ontology extension.
5.2 Ontology as Configuration, Not Code
A critical advantage of ontologies is that they allow enterprise AI systems to scale through semantic configuration rather than application code development.
Without ontologies, every new domain, new Scope Question, workflow variation, or enhancement typically requires new code, new prompts, or specialized agents. Over time, this leads to agent sprawl, increasing complexity and maintenance costs.
With an ontology-driven architecture, the core agents and orchestration framework remain largely unchanged. New Spheres, Scope Questions, and business concepts are introduced by extending the ontology and its system-of-record mappings rather than building new agent logic.
As a result, the platform scales by adding config rather than adding code. This accelerates domain onboarding, improves agility, and prevents the proliferation of domain-specific agents and workflows.
5.3 The Ontology Lifecycle
Automated ontology generation, continuation protocol, and human review process together defines a continuous lifecycle:
Bootstrap: The ontology generator produces an initial domain ontology from Scope Questions, domain description, and optional data models. The output is immediately usable, it has already passed the coverage gate and structural validation, but every concept is marked as provisional.
Validate: Human ontologists verify semantic accuracy, correct misinterpretations, and add institutional nuance. Entities are promoted from provisional to validated status, with reviewer identity and rationale recorded in the changelog.
Extend: As the system is used, continuation questions trigger ontology extension through inference, autonomous data-model exploration, or user interaction. New entities enter the lifecycle as provisional and follow the same validation path.
Refine: Usage-pattern analysis, interaction-driven learning, and data-driven discovery continuously surface refinements: entities that should be split or merged, relationships that are missing or incorrect, and assumptions that have been invalidated by new data.
Govern: Every change ,whether generated, learned, or human-authored, passes multiple verification gates before integration: description-logic reasoner consistency; SHACL constraint validation; upper-ontology alignment; a downstream impact estimate (high-impact deltas require engineer approval regardless of confidence score); competency-question regression, in which the SPARQL queries that originally proved scope-question coverage are re-run so the ontology can never silently lose the ability to answer a question it once answered; and provenance completeness. Removal of any element additionally requires explicit engineer approval. Updates add and refine, they never silently degrade.
This lifecycle ensures that the ontology is never finished in the traditional sense but is always in a known state of maturity. An agent can distinguish between reasoning grounded in validated, well-established ontological entities and reasoning that relies on provisional, recently generated ones, and can communicate this distinction to the user as part of its explainability metadata.
The Two Foundations of Decision Infrastructure
The architecture described in this blog rests on two foundational ideas that are worth separating clearly.
The first is the Scope Question as the unit of ontological work. Scope Questions are how domain ontologies get created, how systems of record get mapped, and how the AI system knows which slice of an enormous enterprise data model is relevant to any given decision. They are the mechanism that makes precision possible at scale.
The second is the system of record as a first-class component of the Decision Infrastructure. Systems of record are not passive data sources. Each one has its own ontology, its own schema, and its own naming conventions. The semantic intermediary layer exists precisely to bridge these systems to the decision context in a way that is governed, traceable, and continuously improving. Connecting the right data to the right decision, reliably and at enterprise scale, is fundamentally a semantic problem disguised as a data problem.
Enterprises have already invested billions of dollars building systems of record. What remains missing is the semantic layer operating across multiple systems of record that allows humans and AI systems to reason consistently across them.
Scope-question based ontologies, system-of-record mappings, and the semantic intermediary layer provide that missing foundation. They reduce cross-system labor, enable trustworthy decision-making, and allow AI systems to operate on enterprise knowledge rather than isolated datasets.
In the next phase of enterprise AI, competitive advantage will not come from access to more data. It will come from the ability to connect meaning across systems, decisions, and domains. Ontologies are the mechanism that makes that possible.




